优化DB2数据库的十个最佳实践(下)
DB2优化技巧 6: 使数字和数据日期类型相匹配
在先前的版本中,对于处理谓词和比较数据类型长度的变化,阶段1 处理是非常精确的。在DB2 v7 之前, 这种不匹配导致了谓词被降级在阶段2 处理。 但是,一个DB2 v7的新特点允许数字化的数据类型可以被手动的转换以避免阶段2 降级。
ON DECIMAL(A.INTCOL, 7, 0) = B.DECICOL ON A.INTCOL = INTEGER(B.DECICOL)
如果两个列都被索引, 会得到到更大的结果集。 如果只有一个列被索引, 就转换同伴。对于促进阶段1,重新绑定索引是必要的。
DB2优化技巧 7: 以表单和谓词类型从最高限制性到最低限制性进行排序过滤
当写一个SQL 语句用到多种谓词时, 确定的谓词将从结果集中过滤掉大多数的数据,并且把那个谓词放在列表的开始。由于采用这种方式排序您的谓词, 这令随后的谓词将会过滤较少的数据。
DB2 默认的优化器将分类您的谓词并将处理那个谓词的情况然后顺序的在下面列出。但是, 如果您的查询引用到多个谓词并且属于相同的种类, 那么这些谓词将以他们被输入的次序来执行。这就是为什么排序谓词是如此重要,排序并且把最大过滤能力的谓词放在序列的顶部(尽最大能力的排序)。在以后的版本中,最终的查询重写将考虑到这些, 但在今天,当您写查询的时候是应该知道这些的。
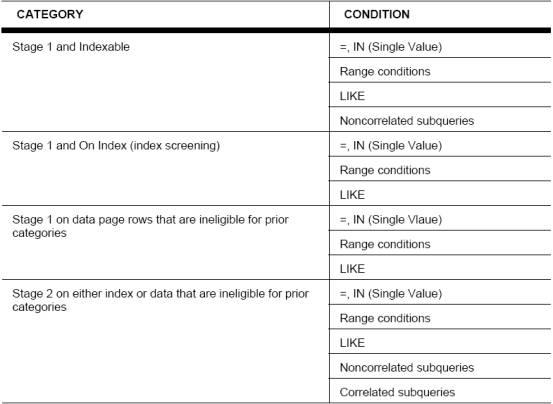
图 5:谓词过滤顺序
WHERE A.COL2 = 'abracadabra'
AND A.COL4 < 999
AND A.COL3 < :hvcol3
AND A.COL5 LIKE '%SON'
最应该限制的条件应该被首先列出, 以便第二种情况的额外处理能够被避免。
DB2优化技巧 8: 删除SELECT表单
被SELECTed 的每一列都消耗了很多资源进行处理。 有几处地方用以检查确定是否列选择的是真正必要的。
例子 1:
WHERE (COL8 = 'X')
如果一个SELECT包含一个谓词,并且列与一个值相等, 那么这一列并不一定必须的为各列检索, 这个值将总是'X' 。
例子 2: SELECT COLA,COLB ,COLC ORDERY BY COLC
DB2 不再要求简单地选择一列去做排序。 所以在这个例子中,如果最终用户不需要那个值,则COLC就不再要求选择。为了避免多余的处理,可以从SELECT列表中删除几条。 它不再被要求去SELECT一些列在ORDER BY 或GROUP BY从句中使用。
DB2优化技巧 9: 已知结果的极限结果集
如果是已知的,这种" FETCH FIRST n ROWS ONLY "子句是应该使用的,最大的行数将被从一个结果集中得到。 这种子句调用一个快速而隐示的关闭,从而限制了从结果集返回的行数。当第n 项结果行被处理完时,页面在缓冲池被迅速的释放。 这种" FETCH FIRST n ROWS ONLY "子句不能调用一个快速而隐示的关闭,并且将保持死锁和取回状态,直到游标隐示或显示地被关闭。 与此相对照的是, " FETCH FIRST n ROWS ONLY "将不会只允许第n+1 列被得到而导致 SQLCODE = 100 。 如果n 是一样的,那么两种子句的优化都是一致的。
DB2优化技巧 10: 分析和调优存取路径
使用 EXPLAIN 或工具来解释 EXPLAIN 的输出, 核实存取路径对于请求的处理是否恰当。在生产子系统中,通过绑定相对应的生产统计检查每次查询的存取路径。缓冲池, RID池, 排序池, 和 LOCKMAX 的阈值也应该类似于生产环境。测试环境里过大的RID池将使RID 池在生产中关闭。 RID 池的关闭可能发生在 List Prefetch、以及多索引存取和 Hybrid Join Type N 存取路径的期间。RID 池关闭会导致全表扫描。
调优查询使用一种技术,将经得起未来更加智能的优化和查询重写的考验。 典型的查询调优可能使用下面的一个或多个技术:
-OPTIMIZE FOR n ROWS
-FETCH FIRST n ROWS ONLY
-No Operation (+0, -0, /1, *1, CONCAT ' ')
-ON 1=1
-Bogus Predicates
-Table expressions with DISTINCT
-REOPT(VARS)
-Index Optimization
所有这些技术都对存取路径的选择有影响。 比较评估多种场景的成本消耗,来检验调优的努力是否成功。
调优成果的目标应该是精确存取路径和优化的索引设计。当有以下任何情况发生的时候,就应该积极主动开始这项持续化的工作:
- DB2 对象数量的增量
- DB2 对象的大小变化
- 动态SQL 的使用的增量
- 事务等级的变化
- 移植
解决方案
Quest Central for DB2是一个集成的控制台,可以提供核心功能,DBA (数据库管理员)需要执行他们日常的数据库管理任务, 空间管理, SQL调优和分析, 并且可以进行性能诊断监视。Quest Central for DB2 是由DB2 软件专家撰写的,并且提供具丰富的功能,以利于视图化的用户界面,并且支持在Unix, Linux,和windows主机上运行DB2 数据库。DB2 的客户不再被要求用独立的工具维护和使用他们的主机和分布式的DB2 系统。
Quest Central 的SQL调优组件提供一个完整的SQL 调优环境。 Quest Central是唯一可以提供完整的SQL 调优环境的针对DB2可用的产品。这个环境包括以下部分:
- 调优实验室:通过场景的使用,一个单独的SQL 语句能够被改进很多次。然后这些场景能够立刻被比较以确定哪个SQL 语句提供了最有效率的存取路径。
- 比较: 您立刻可以看出对于SQL 语句修改的性能改变效果。 由于比较多个场景, 您能看到对CPU 的效果, 消耗的时间, I/O 和其他更多的统计。另外数据的比较将保证您的SQL 语句返回相同的数据子集。
- 建议:由SQL 调优组件提供的建议,将会发现所有的在白皮书指定的条件等等。 另外, 如果一个新场景可以利用,SQL 调优组件甚至将会重写SQL ,并综合选择的建议。
- 存取路径和对应的统计:在SQL的上下文中,对于DB2存取路径,所有适合的统计应被显示出来。 采取推测以设法理解为什么选择一个特殊的存取计划。
Quest Central for DB2 健壮的功能显现了上述SQL 调优中的技巧以及更多。 这篇白皮书剩余的部分将证明 Quest Central 是由更丰富和更透彻的知识恰当的组成的。 Quest Central 不仅可以提高您的SQL语句效率,更可以帮助您全面的提升数据库的性能。上面描述的各种调优技巧都被Quest Central所包括。
解决的技巧 6:使数字化和日期数据类型相匹配
这个特殊的SQL 难题可能是最细微及最难被察觉的,特别是当使用主机变量的时候。 解释也许能显示索引存取的使用, 但在完成查询之后将采取表空间扫瞄。 这是常见的情况,当谓词比较两个项目的值并且那两个项目包含着不恰当的数据类型时。 Quest Central SQL Tuning 将在建议部分识别这种情况。 另外, 数据库管理组件能够修改列, 既使本地的DDL不支持修改(由卸载数据,删除表, 重载数据, 和重新绑定) 。
解决的技巧 7:以表和谓词类型从高限制到低限制进行排序过滤
SQL 调优被设计成允许测试这些条件的类型以确定适当的顺序。
例子 1:
SELECT * FROM batting
WHERE run_qty > 2
AND hit_qty > 10
这条SQL 被放入工具中并被放置在最初的SQL表中。hit_qty 列比run_qty 谓词能提供更好的过滤。 一个新场景被创建并且谓词以hit_qty 谓词的顺序被首先列出。
解决的技巧 8: 删除SELECT的名单
当返回数据给用户时,选择比需要多的列会导致更多的消耗将会。 由于使用SQL 调优的场景特征, 您能修改最初的SQL语句以删除多余的列并且执行消耗比较来确定删除多余列的影响。 在下面的例子中, SQL 语句被修改以减少返回的列数。 在原始的SQL 语句和修改过的语句间的节省大约有60% 。 这种节省对大型数据库有着巨大的影响。
解决的技巧 9:已知结果的极限结果集
为了确定加入了"FETCH FIRST n ROWS ONLY"子句的影响,将安排您的SQL 语句, 您可以把您最初的SQL 语句放入SQL 调优组件中。 从而创建一个新场景和包括"FETCH FIRST n ROWS ONLY"子句。 比较将显示由于增加这条从句而获得的成本节省。
解决的技巧 10:分析和调优存取路径
存取路径标签在SQL 调优中被发现,并为您存取路径提供全面的显示。 在执行第一步时,存取路径是自动地突出,并且"next step"按钮将突出在下一步, 您按步骤执行存取计划的每一步。
业内最健壮的显示在将清楚而准确的描述您的SQL 语句的存取路径。
结论
这是检查 SELECT 语句最小范围的列表,应该被优先完成,适合在任何一个的OS/390和z/0S Version 7的DB2产品环境中。这些源自于目前DB2处理查询组件的知识。这个列表将随着DB2的版本的变化而变得更加完善。工具能帮助你检查这其中的许多建议是否真实有效。
(北京铸锐数码科技有限公司 www.InnovateDigital.com)