Oracle性能问题预测方法
关于预测方法
根据以上讨论,尤其是需求与竞争之间的关系,我们预测 Oracle 性能问题的方式有两种:
* 识别出以增长的速率消耗资源或在一段时间内表现出响应时间变慢的 SQL 语句。对于这些 SQL 语句,根据发展趋势识别出需要现在进行调整的 SQL,以避免将来出现问题。
* 识别出接近容量极限以及以后会形成瓶颈的数据库资源(锁、锁存器、I/O 通道等)。这些资源需要增加容量或提高利用率以达到计划的需求。
预测模型:为何少即是多
预测性能的直观方式就是尝试创建所研究系统的“完美”模型。其中可能涉及分别对应用程序中每条 SQL 语句以及SQL 语句中的每个步骤建模。每个步骤都可以根据其性能与底层数据量的关系建立自己的模型,这些数据量会使用当前和预期的事务率并根据归档和保留策略来分别预测。然后当随意模拟 SQL 执行速率时,无数的模型就会用于成本模拟;完美模型将使用队列理论并根据磁盘、CPU 等的响应时间特性来计算所用时间,然后预测可能发生的瓶颈并对其建立模型。我们还可以使用时间序列分析并根据天、周、月、季、年来进一步对 SQL 执行速率的波动建立模型。图 5 描述了这类模型的某些元素。
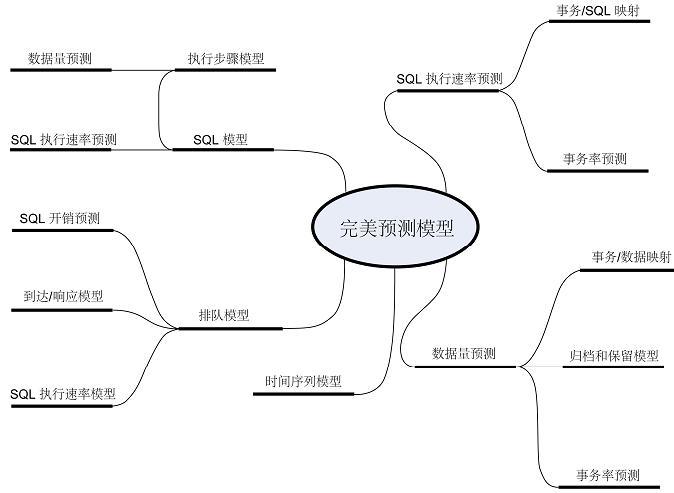
图 5. “完美”(理论上的)预测模型的元素。查看大图
图 5 说明“完美”模型实际上使用了多个模型来模拟一切。这样就可以同时兼顾精度和准确度。但随着模型的假设数量、模型的复杂度和精度的增加,准确性及真实性反而会降低。
此外,人根本无法对这些复杂的模型进行“健全性检查”。模型的复杂性和多维性迫使用户相信其正确性,而不是通过判断和经验对预测模型进行验证。研究表明,随着信息量的增加,人类决策的准确性反而会降低。
最后,完美模型建立在多个被细化的预测模型之上:将来事务率、事务的 SQL 故障、数据量大小给定的事务率以及归档策略等。如果无法正确建立这些模型,完美模型也就无法实现,况且要建立这些基础预测模型,几乎是不可能的。
因此,假设数量和变量较少的模型更可能做出准确(虽然可能不那么具体)的预测,并且更为可行。所以我们不应在模型中涉及大量的变量,而应使用预测价值更高的少量变量。
测量和建模
我们“少即是多“原理鼓励我们使用少量的变量来表示 SQL 的执行成本,或可用来预测将来执行时间和竞争开销的竞争指标。
测量 SQL 语句成本
SQL 的“成本”是什么? 从商业角度看来,成本可能最准确地反映在所用时间上,同时它又制约着响应时间和吞吐量— 这两个术语常常与服务等级协议 (SLA) 有关。
然而,所用时间是个“变数多”的量:它可根据其他 SQL 语句所施加的负载以及数据库高速缓存的有效性而变化(由于数据库高速缓存中存在必要的数据,因此同一 SQL 语句在第二次执行时通常要快得多)。同样,磁盘 I/O 也不是理想的成本指标。
CPU 消耗是个变数少的指标,但由于某些类型的 SQL 是受 I/O 限制而非受 CPU 限制的,因此它只适用于所有相关SQL 语句的一部分。
最佳单个成本变量可以是逻辑读取次数:满足 SQL 所需的数据块的数量。该变量是比较稳定的;如果 SQL 实际不消耗更多资源,逻辑读取次数是不会增加的。除此之外,逻辑读取速率与 CPU 和磁盘 I/O 密切相关—在试图满足逻辑 I/O 需求时会使用大多数的 CPU 和 I/O。
因此,如果说所用时间、物理 I/O 和 CPU 时间在某些情况下是比较适合的指标,那么逻辑读取次数则是最可靠的 SQL语句成本指标。
测量瓶颈
瓶颈通常表现为等待某一资源变为可用所用的时间。例如,另一用户正在更新某个表,而您必须等待该表被解锁,或者过量的 I/O 需求意味着您必须等待磁盘处理您的 I/O 请求。
Oracle 的等待接口使我们可以更好地理解在这些等待条件下所使用的时间量。一旦会话让出 CPU 以等待资源可用,所花费的等待时间就被记录在诸如 V$SYSTEM_EVENT 的表中。
等待接口可以通过以下两种方式发现瓶颈:
* 某些等待类别(如锁和锁存器)总是表示某种程度的竞争。通过跟踪这些等待时间,我们可测量出所产生的竞争量。
* 其他等待类别(尤其是 I/O )可反映正常活动。然而,我们知道正常情况下这些请求的发生频率。例如,在 典型的磁盘设备上,5ms 的 I/O 等待时间是正常的,而 20ms 的等待时间则表明设备存在竞争。因此对于这些类别,如果平均服务时间增加了,即表示竞争增加了。
构建模型
我们可以预测 SQL 语句性能和竞争量中的静态、线性、对数或指数趋势。
此外,由于 SQL 执行速率和数据量经常一起增加,我们还可观察到两者之间因相互作用而产生的指数关系。如果每次执行的成本都在增加且执行频率更高,则可能导致 SQL 的总成本呈指数增长,从而给有限资源带来更多竞争。
因而,我们首先判断在我们的成本变量和我们的预测量之间是否存在关系。然后我们尝试判断它们的大致关系:线性、指数、对数或静态。最后,我们尝试构建数据的最适合直线或曲线。
统计方法
“完美”模型需要使用高级统计建模技术,而我们的简洁方法可采用被广泛了解的统计技术。主要技术包括:
* 相关性,允许我们判断变量间是否存在任何关系
* 部分相关性,允许我们消除同时与其他变量存在关系的两个不相关变量间的伪相关
* 回归,可以确定“最适合直线”
* 多变量非线性回归,可以确定多个预测变量以及“最适合曲线” 这些技术的优点在于:容易理解、关于底层数据的假设少(如果有)。3
以下两种技术经常用于完美模型,但我们的方法不会采用:
* 时间序列分析是一种检测底层数据中循环模式的技术。例如,时间序列分析通常预测工作周中活动的高峰期和低谷期,并可预测在(例如)季末期的高峰负载次数。不幸的是,大多数时间序列分析技术与非线性回归分析不兼容:很难同时准确地预测出周期性和总体系统趋势。除此之外,只有在经过大量周期后才能准确地预测出周期性趋势。虽然一周中的高峰可能只需数月的数据即可检测到,但季末高峰则需要连续几年的数据才能建立。
* 排队理论对等待资源所用时间量对响应时间的影响建立模型。例如,逝去时间可能并不仅仅是执行 CPU 和 I/O 活动所用的时间,还可能包括等待那些资源变为可用状态所用的时间。不幸的是,在真实世界中,超长的队列通常会使性能几乎不可预测。其结果不是系统慢,而是没有响应。
此外,随着队列长度的增加,通常会因超时或事务中断而造成需求(或到达率)减少。如果发生排队现象,事务率将会下降,就如同您不会进入排着长队的商店,或当队列移动过于缓慢时您会放弃排队。因此我们相信,数据库系统的目标应该是避免资源耗尽,而不是对排队等待就占据大部分响应时间的系统进行性能预测。识别出不可扩展的 SQL 无疑是通向此目标的第一步。
预测区间
一旦我们建立了关系类型,统计技术就会帮助我们确定任意数据的最适合直线或曲线。然而,将来 SQL 的实际成本将随当时事务率和数据量的波动而变化。没有哪种统计技术可以基于历史趋势建立一个准确的值,但可以预测出一个范围值。围绕预测值的范围值称为预测区间。通常情况下,置信区间表示存在将来值落在指定范围内的某种可能性(通常是95%)。
传统统计推断技术所计算出的默认预测区间假设在过去检测到的趋势将无变化的适用于将来。例如,如果在过去 3 个月中数据量以 150% 的速度稳步增长,则假设在未来 3 个月中数据量将以同样的速度增长。 这些假设也许成立,但业务动态的变化也常常会引起(通常是所期望的)应用程序使用模式的变化。随着时间的推移,应用程序模式变化的可能性会越来越大,因此在模型延伸至将来的同时有必要扩大预测区间的范围。
图 6 显示在 Quest Software 的 Spotlight on Oracle 产品中,预测区间是如何表示的。随着时间的推移,预测区间越来越大。

图 6. 预测区间。 查看大图
检测趋势变化
预测区间使我们可以将系统中的预期变化考虑在内。我们知道我们的模型并不完美,并且我们也知道将来的变化与过去多少会有差异。因而,某些因素可使我们的模型彻底无效。这些因素包括:
* 底层硬件的变化
* 软件层的变化(例如操作系统或 RDBMS 升级)
* 数据量的骤变(例如,大量数据负载)
* 物理数据架构的变化(例如新索引)
* 优化器重新计算引起的 SQL 执行方案的变化
其中任意因素的变化都会导致单个 SQL 语句或整个系统总体趋势的变化。如果不考虑趋势的这些变化,则统计技术可能会就底层趋势得出无效的结论。
图 7 说明了这一现象。索引架构的变化导致了 SQL 语句成本的变化。如果不考虑这一点,则反应出的将是非线性(指
数)趋势。
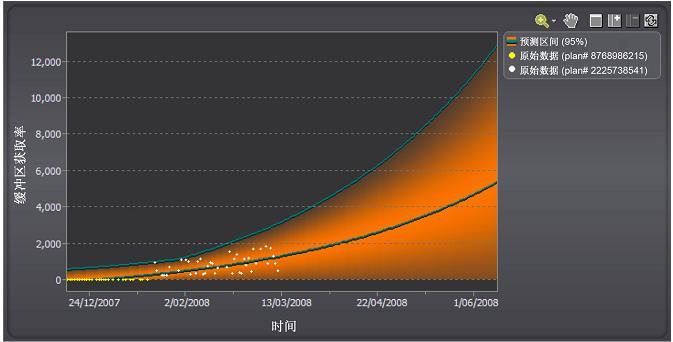
图 7. SQL 方案的改变可使预测失真。查看大图
如果考虑趋势的变化,即可生成更正确的线性趋势,如图 8 所示。
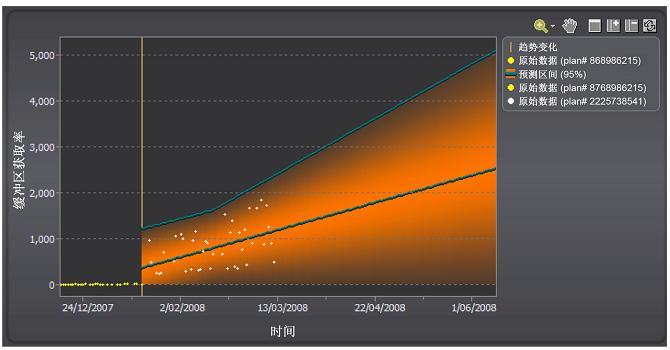
图 8. 将 SQL 执行中的趋势变化考虑在内。查看大图
结论
当发生 Oracle 性能问题时再采取应对措施的策略永远会对业务造成不可接受的影响。在 Oracle 性能管理中,我们的目标应该是预测可能出现的性能问题并避免该问题对业务造成影响。
反应性的 SQL 调整正迅速走向削减投资回报的处境;对于充满变数的未来,这仍将是个至关重要的任务,但现在的技术已经非常成熟,不需要根本性的改进。预测性的 SQL 调整似乎成了另一个难题:预测将来的 SQL 性能,旨在避免 SQL性能相关问题的发生。
此外,由于可预测出有限的数据库资源将会产生瓶颈,从而可使 DBA 对系统进行适当的配置以更有效地使用这些有限资源,或者增加可用资源的数量。
在本文中,我们介绍了一种可提供此类预测能力的实用方法。这些原则已在 Spotlight on Oracle 和 Spotlight on RAC 产品中得以实现。